Detecting Generated Text
Insights from EMNLP 2023

In the Spring 2023 semester, Yutian Chen, Yiyan Zhai, and I worked on a question that, by the time we presented it at EMNLP that fall, had stopped being academic: when a passage of text shows up in front of you, can you tell whether a person wrote it or a language model did, and if the latter, which model? Our paper Token Prediction as Implicit Classification for Identifying LLM-Generated Text argued that you can do this surprisingly well by leaning into what language models already know how to do, rather than by bolting a classifier on top.
This post is the practitioner’s version of that paper.
Detection as next-token prediction
The standard way to build a text classifier on top of a transformer is to take the final hidden state, run it through a small MLP head, and train the whole stack with cross-entropy on the head’s logits. It works, and it is what most detectors in this space do.
We did something else. We picked five tokens that T5’s vocabulary already reserves but does not use, the <extra_id_0> through <extra_id_4> placeholders, and assigned one to each of our five source classes: human, GPT-3.5, PaLM, LLaMA-7B, and GPT-2. The model is trained as if it were doing seq2seq generation, with a passage as input and the corresponding label token as the entire target output. At inference we call .generate(max_length=2) and read off whichever label-token argmax falls out.
The classifier is the language model. There is no head. The probabilities over our five labels are just the probabilities the LM places on those token IDs after reading the input. This is the entire trick.
The reason it works, we think, is the inductive prior. T5 has spent its pretraining learning a token distribution shaped by an enormous amount of English text. Asking it to pick among five reserved tokens means we are asking it to do exactly the thing it is already best at, conditioning on context to choose a token, just with the vocabulary collapsed to five points. A randomly initialized MLP head, by contrast, has to learn a feature space from scratch on top of representations that themselves were tuned for a different objective. Same capacity, used differently.
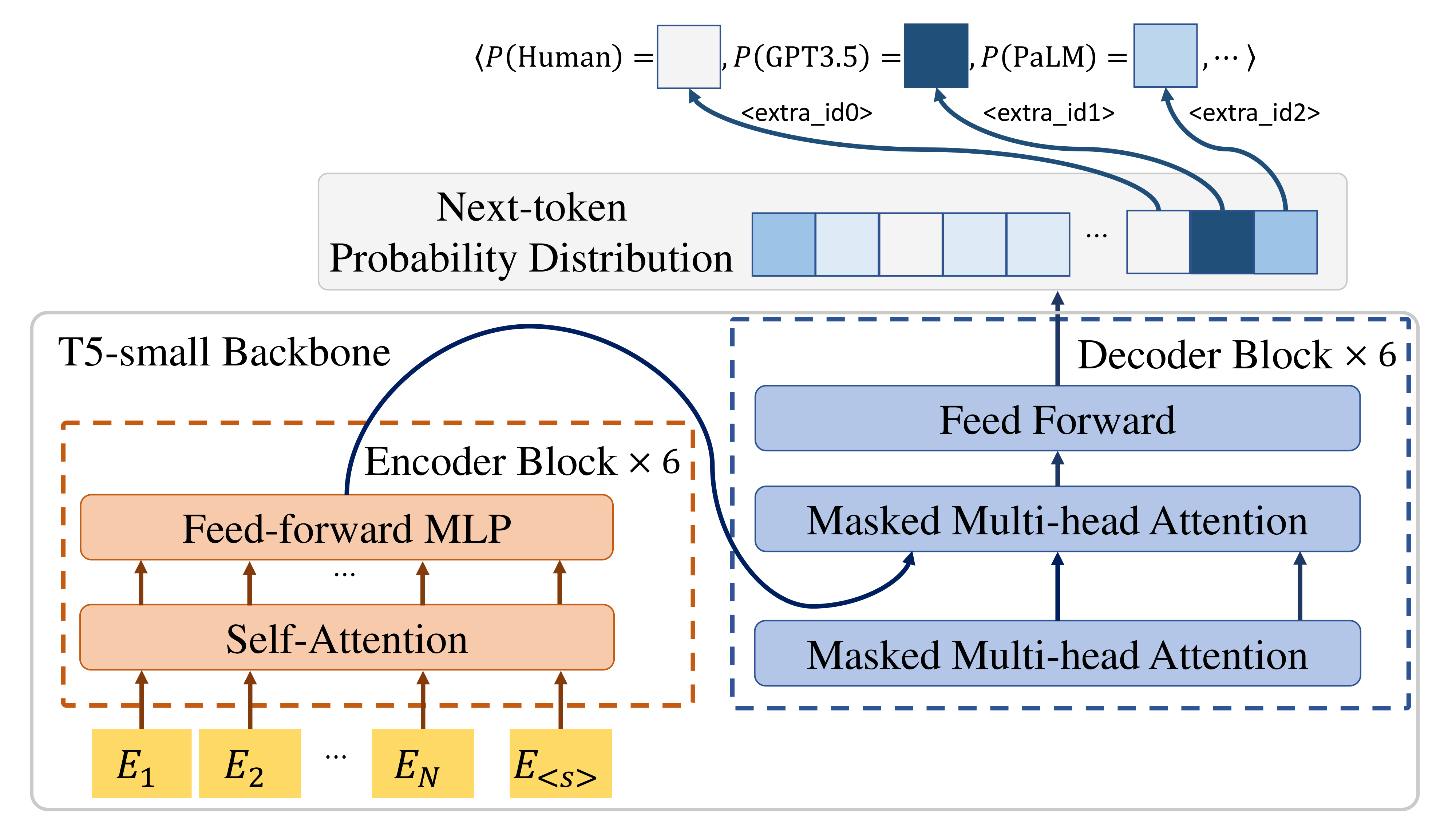 The detector reads a passage and emits one of five reserved label tokens; nothing else is ever predicted.
The detector reads a passage and emits one of five reserved label tokens; nothing else is ever predicted.
Building OpenLLMText
To study cross-model detection we needed a corpus where the same kind of human prompt was paired with completions from each LLM we wanted to cover. We built it ourselves and released it as OpenLLMText, 344,530 samples across five sources, roughly balanced.
The human passages came from OpenWebText, a Reddit-derived web corpus. For GPT-3.5 (gpt-3.5-turbo) and PaLM (text-bison-001) we used the prompt “Rephrase the following paragraph by paragraph” and let them rewrite the human passages, sampling at temperature 1.0 and 0.4 respectively. LLaMA-7B is a base model, so we matched its strength by using it in completion mode: the first 75 tokens of a human passage as the prefix, with continuations of at least 42 tokens kept. GPT-2 samples came from the pre-existing GPT2-Output corpus.
Training T5-Sentinel
The detector is T5-Small, the 60-million-parameter variant. Inputs are truncated to 512 tokens. We train with AdamW at learning rate 1e-4 and weight decay 5e-5, for 15 epochs on a 264k-sample training split. Effective batch size is 128, reached by accumulating gradients over eight mini-batches of sixteen on a single GPU. The loss is the standard T5 sequence-to-sequence cross-entropy; the only nonstandard thing is that the target is always exactly one token long.
A small implementation note. Because we reuse T5’s pre-existing reserved-token IDs (32095 through 32099) rather than appending new tokens to the vocabulary, no embedding-table resize is needed. Those IDs already carry pretrained embeddings, which the model specializes during fine-tuning, and that reuse seemed to help training in practice.
What worked, and the comparison that mattered
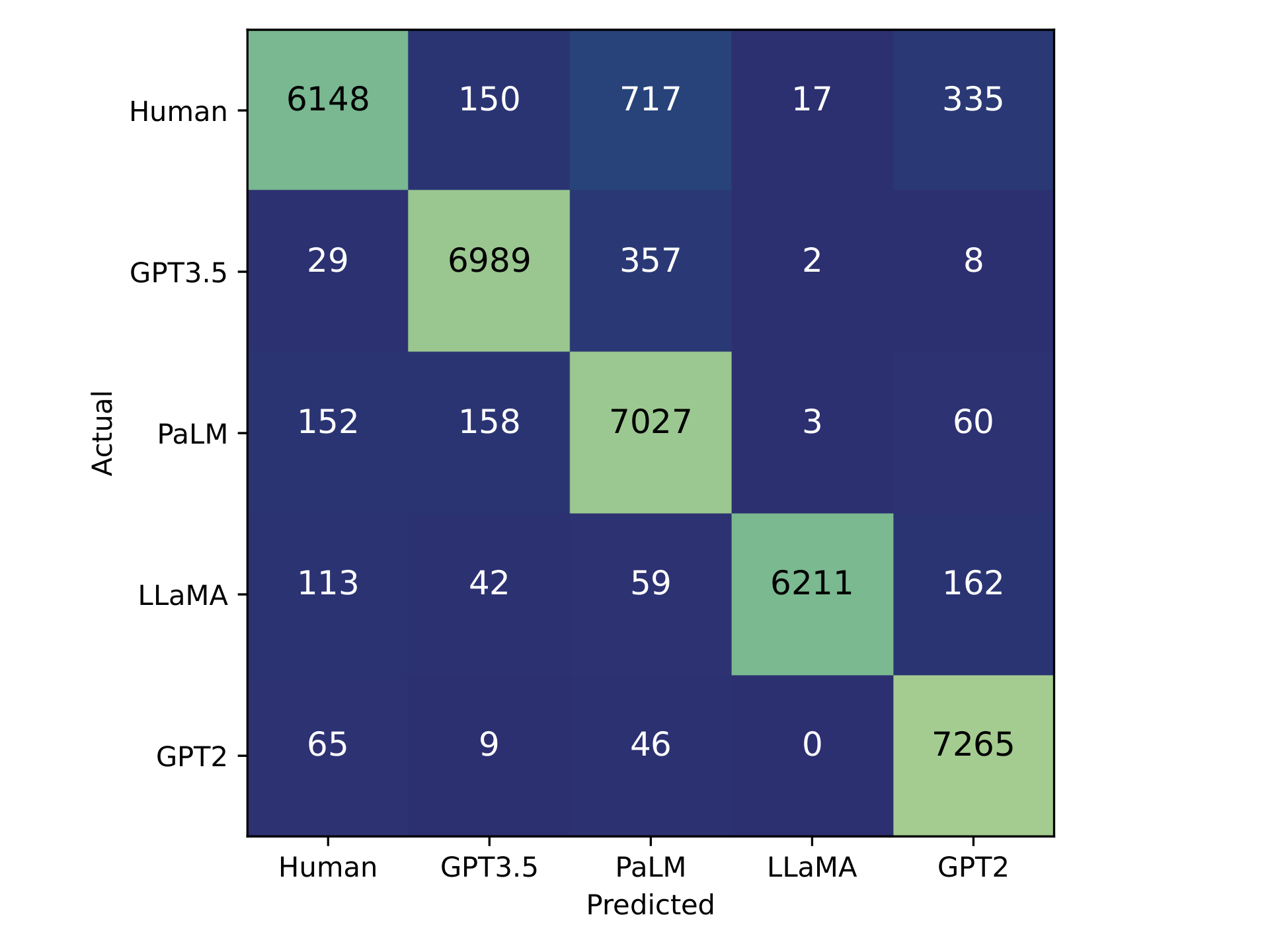
On the held-out test set, T5-Sentinel reaches a weighted F1 of 0.931 across the five-way classification, and on the collapsed human-versus-any-LLM binary task it lands at F1 0.886 with AUC 0.965. Against external detectors evaluated on the same data, this is comfortable: OpenAI’s classifier sat at AUC 0.795 and F1 0.415; ZeroGPT at AUC 0.533 and F1 0.134.
The comparison we cared about more was internal. We trained a second model called T5-Hidden, identical in every way except that it pulls the final decoder hidden state and runs it through a three-layer MLP head, the conventional architecture. Same backbone, same data, same hyperparameters. T5-Hidden lands at weighted F1 0.833, versus T5-Sentinel’s 0.931. The per-class AUCs are nearly identical, but the per-class F1s diverge sharply; on LLaMA in particular, T5-Sentinel sits at 0.969 and T5-Hidden at 0.616.
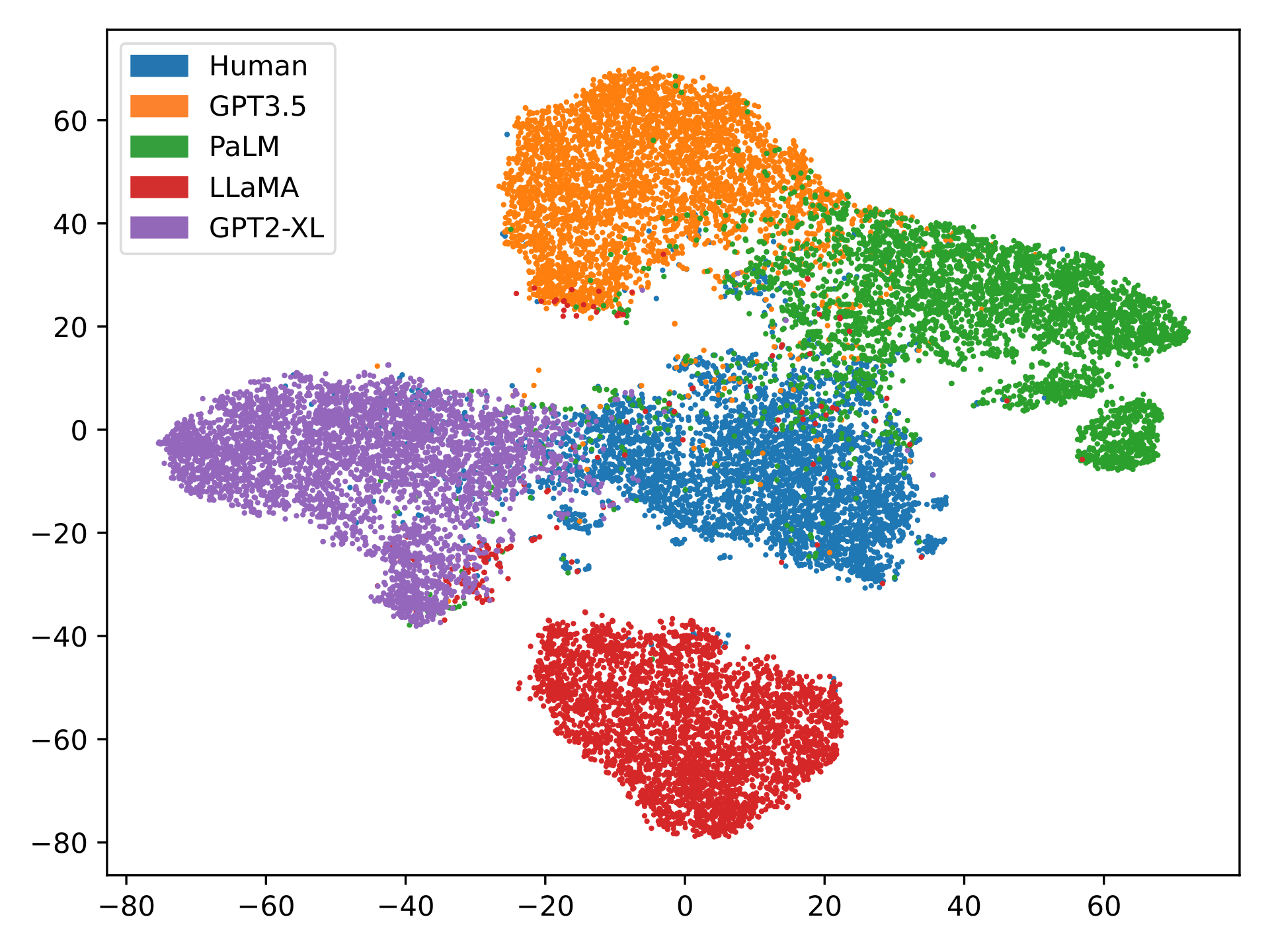
What that told us is that the gap is not about the backbone learning different features. It is about how those features are read out. The token-prediction readout, which has a strong prior from pretraining, is more robust at threshold-sensitive operating points than a freshly-initialized classifier head. The matched AUCs say both models rank examples similarly; the F1 split says the head finds it harder to separate classes at a fixed decision boundary.
We also ran an integrated-gradients analysis with one hundred integration steps to see what the model was attending to. The model survives stripping every punctuation mark from the input; the attribution maps line up with clause structure and verb patterns rather than surface tokens. The model is, to first order, learning syntax.
Closing notes
This started as the term project for 11-785: Introduction to Deep Learning, and was the first time I worked on something that ended up at a conference. The implementation is open source as T5-Sentinel, the dataset is hosted on Zenodo, and the paper is on ACL Anthology. I am grateful to Liangze Li for advising us through the project, and to Professor Bhiksha Raj, whose presence in our weekly meetings shaped what the paper became.
The technical takeaway, for me, is that the most useful thing a pretrained model gives you is often not its representation but its prior. T5-Sentinel works because the model already knows how to do exactly the thing we are asking it to do, predict one token given context, and we lean on that.