As large language models (LLMs) like GPT-3.5, PaLM, and LLaMA continue to evolve, distinguishing machine-generated text from human writing has become a critical challenge. At EMNLP 2023, my team presented an innovative solution to this issue: Token Prediction as Implicit Classification for Identifying LLM-Generated Text.
Why Detecting LLM-Generated Text Matters
The rapid advancements in generative models open up remarkable opportunities, but they also raise pressing concerns:
-
Mitigating Misinformation: LLMs can inadvertently amplify inaccuracies, biases, or falsehoods embedded in their training data. Such content, when presented as authoritative, can mislead audiences and erode trust.
-
Combating Malicious Usage: The scalability of LLMs enables malicious actors to fabricate news, impersonate individuals, and manipulate public discourse. From spreading fake health advice to fueling political propaganda, the risks are substantial and far-reaching.
-
Preserving Academic Integrity: In education, LLMs are sometimes misused by students to complete their assignments, undermining the learning process and skill development. This poses challenges like plagiarism, jeopardizing academic honesty and genuine learning.
Despite these risks, LLMs also bring transformative benefits when used responsibly. They enhance productivity in programming (e.g., GitHub Copilot), refine writing processes, and streamline workflows in various fields.
Fun fact: This blog post was drafted by me and then refined by LLMs before publishing!
Our Approach: Leveraging Token Prediction for Detection
Existing methods for detecting machine-generated text often rely on external classifiers or heuristic-driven algorithms, which can be resource-intensive and prone to biases. Our approach takes a different route: harnessing the inherent capabilities of LLMs for next-token prediction to reframe the classification as a sequence completion task.
At the core of our method, we introduce “labeling tokens”—specialized markers that not only indicate whether the text is human- or LLM-generated but also identify the specific LLM responsible (e.g., GPT-3.5, PaLM, or LLaMA). A detection model, essentially another language model, analyzes the text and predicts the next token, selecting one of these labels. This approach eliminates reliance on external classificers and fully exploits the intrinsic strengths of LLMs.
The Experiment: Building the T5-Sentinel Model
For our experiments, we fine-tune the T5 model to perform the classification task. While any large language model could theoretically serve as a detector—since all LLMs predict the next token based on context—we chose T5 for its roubustness on seq2seq tasks.
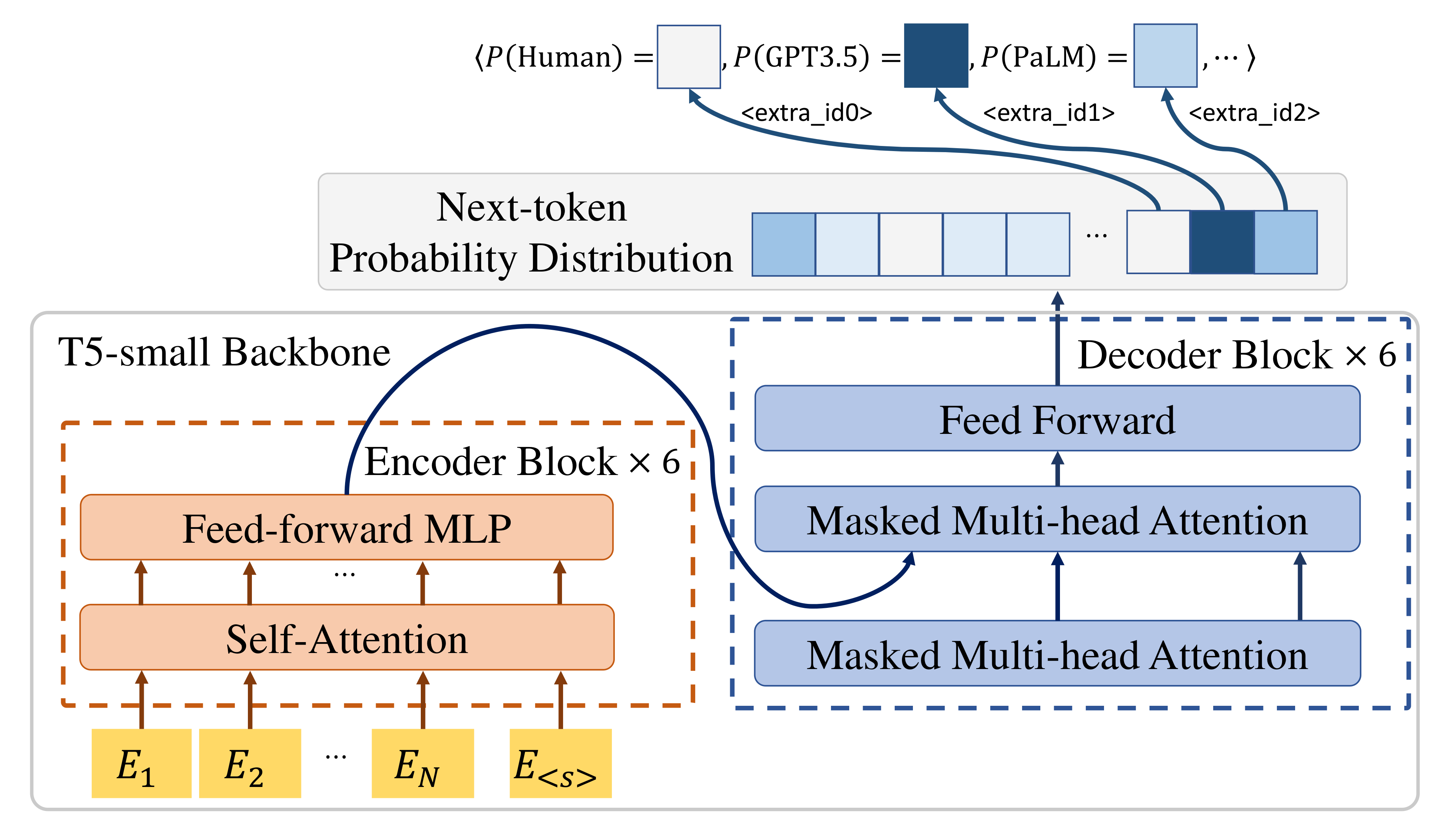 T5-Sentinel model architecture.
T5-Sentinel model architecture.
Our custom dataset, OpenLLMText, includes 340K samples from human authors and various LLMs (e.g., GPT-3.5, PaLM, LLaMA, GPT-2). The human samples were sourced from the OpenWebText dataset, while LLM-generated samples were created by rephrasing human-authored passages.
We evaluated the model using metrics like Receiver Operating Characteristic (ROC) curves, AUC, and F1 score. Our fine-tuned T5-Sentinel achieved a weighted F1 score of 0.931, outperforming a baseline classifier (F1: 0.833). Further analysis showed that our model effectively discriminates between human writing and machine-generated text, as illustrated by the confusion matrix and t-SNE plot.
Looking Ahead
This research began as a semester-long project for 11-785: Introduction to Deep Learning and quickly evolved into a full-scale exploration of ethical AI challenges. With the recent rise of tools like ChatGPT, we aimed to address the societal implications of LLMs—both their immense potential and their risks.
This work was made possible through the collaboration of our team, Yutian Chen, Yiyan Zhai, and myself. We’re grateful to receive the guidance from PhD student Liangze Li, now a research engineer at Google DeepMind, and Professor Bhiksha Raj, whose expertise was instrumental.
Explore More: Read our full paper on Token Prediction as Implicit Classification for Identifying LLM-Generated Text and check out the implementation on GitHub: T5-Sentinel.